AI-Agenten (englisch für „Artificial Intelligence Agents“) und KI-Agenten (deutsch für „Künstliche Intelligenz-Agenten“) repräsentieren Technologien, die autonom agieren können, um spezifische Aufgaben zu lösen. Obwohl die Begriffe synonym verwendet werden, liegt der Fokus bei beiden Konzepten oft auf unterschiedlichen Anwendungsfeldern und Umsetzungen. Dieser Artikel erklärt die Unterschiede, Einsatzmöglichkeiten und die Zukunftsperspektiven dieser Technologien.
Was ist ein AI/KI-Agent?
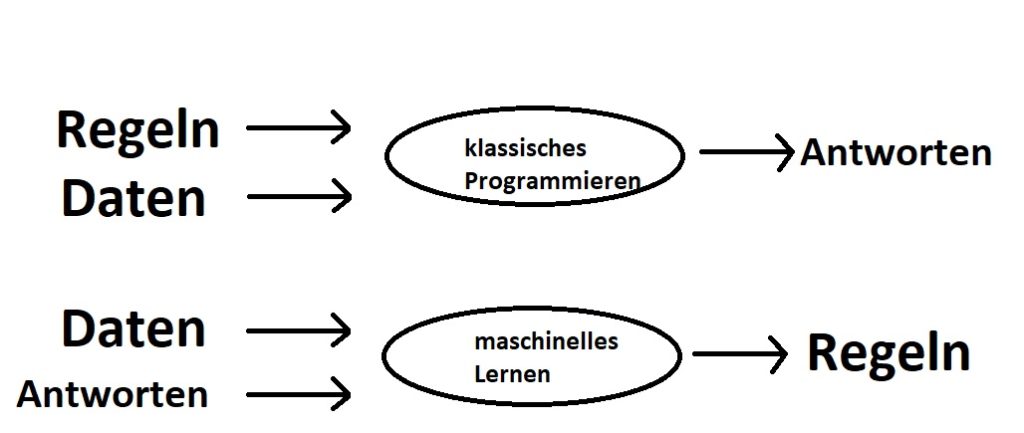
Ein AI- oder KI-Agent ist ein Softwareprogramm, das in einer definierten Umgebung agiert, um Ziele zu erreichen. Er nutzt Wahrnehmung, Entscheidungsfindung, Lernen und Handeln, um komplexe Aufgaben autonom oder mit minimaler Nutzerinteraktion zu bewältigen.
- Autonome Fähigkeiten: KI-Agenten können Daten analysieren, Entscheidungen treffen und Aufgaben durchführen, ohne ständigen Input durch einen Nutzer.
- Lernfähigkeit: Sie lernen aus Erfahrungen und passen ihre Strategien an neue Anforderungen an.
Beispiele sind autonome Fahrzeuge, die selbstständig navigieren, oder Systeme zur Automatisierung von Unternehmensprozessen wie Lieferkettenmanagement oder Produktentwicklung.
Unterschiede zu Chatbots und AI-Assistenten
KI-Agenten werden oft mit Chatbots oder AI-Assistenten verwechselt. Doch ihre Fähigkeiten gehen über einfache Skriptabläufe hinaus:
- Chatbots: Reagieren auf Anfragen basierend auf vordefinierten Regeln. Sie sind ideal für einfache Interaktionen wie FAQs, aber begrenzt bei komplexen Aufgaben.
- AI-Assistenten: Unterstützen bei alltäglichen Aufgaben wie Terminplanung. Ihre Lernfähigkeit ist oft beschränkt, da sie in erster Linie reaktiv agieren.
- KI-Agenten: Diese Systeme sind proaktiv, analysieren Umgebungen und treffen eigenständige Entscheidungen, z. B. in der Finanzanalyse oder beim autonomen Fahren.
Anwendungsfelder von KI-Agenten
KI-Agenten haben ein breites Spektrum an Einsatzmöglichkeiten:
- Autonomes Fahren: Systeme wie Tesla Autopilot treffen in Echtzeit Entscheidungen, um Fahrzeuge sicher zu navigieren.
- Produktentwicklung: Unternehmen nutzen KI-Agenten, um Markttrends zu analysieren und innovative Produktideen zu entwickeln.
- Kundensupport: KI-Agenten bieten maßgeschneiderte Lösungen, indem sie Kontext und Nutzerhistorie berücksichtigen.
- Gesundheitswesen: Personalisierte Behandlungspläne und Diagnosen werden durch lernfähige Agenten verbessert.
- Finanzwesen: Autonome Handelsagenten analysieren Markttrends und führen Entscheidungen in Millisekunden aus.
Technische Mechanismen
Die Funktionsweise von KI-Agenten basiert auf folgenden Prinzipien:
- Wahrnehmung: Daten werden über Sensoren oder Schnittstellen gesammelt und analysiert.
- Entscheidungsfindung: Algorithmen bestimmen die beste Handlung basierend auf Zielvorgaben.
- Lernen: Durch maschinelles Lernen, z. B. überwacht, unüberwacht oder durch Verstärkungslernen, verbessern sie ihre Effizienz.
- Handeln: KI-Agenten interagieren mit ihrer Umgebung über definierte Aktuatoren oder APIs.
Herausforderungen und ethische Überlegungen
Die Implementierung von KI-Agenten birgt Herausforderungen:
- Datenschutz: Sensible Nutzerdaten müssen durch starke Verschlüsselung und Einhaltung von Gesetzen wie der DSGVO geschützt werden.
- Bias und Fairness: Algorithmen müssen so gestaltet werden, dass sie keine diskriminierenden Entscheidungen treffen.
- Fehlentscheidungen: In autonomen Szenarien, z. B. bei selbstfahrenden Autos, können Fehler schwerwiegende Folgen haben.
Zukunftsperspektiven
Die Technologien von KI-Agenten entwickeln sich rasant. Durch Fortschritte in maschinellem Lernen und neuronalen Netzen werden sie zunehmend in der Lage sein, Aufgaben in verschiedenen Sektoren autonom zu bewältigen. Die Integration von KI-Agenten in bestehende Systeme kann Effizienz, Präzision und Nutzererfahrungen erheblich steigern.
Die Unterscheidung zwischen AI-Assistenten und KI-Agenten könnte in Zukunft verschwimmen, da beide Technologien immer umfassender werden.
Quellen:
AllAboutAI: Vergleich von AI-Agenten und Chatbots.
Ambersearch: Beispiele für KI-Agenten in Unternehmen
Künstlich-Intelligent: Mechanismen und Arten von KI-Agenten
THPARK: AI Assistants vs. AI Agents